


Graph learning has been used in a wide array of applications from protein folding and fraud detection to drug discovery and recommender systems. Graph data can naturally express the relationships between objects in the real world and it also has strong representation and interpretability. Graph relationships are complex and the quantity of data is huge, usually involving hundreds of vertex and edge types, billions of vertices, and tens of billions of edges.
Therefore, an efficient graph neural network (GNN) system is needed to process time-consuming graph data computing tasks. In addition, the GNN system must be flexibly scalable to support rapid development of GNN algorithms.
The MindSpore graph learning framework provides such a GNN system. The framework has been jointly developed by the James Cheng team at the Chinese University of Hong Kong and the Huawei MindSpore team.
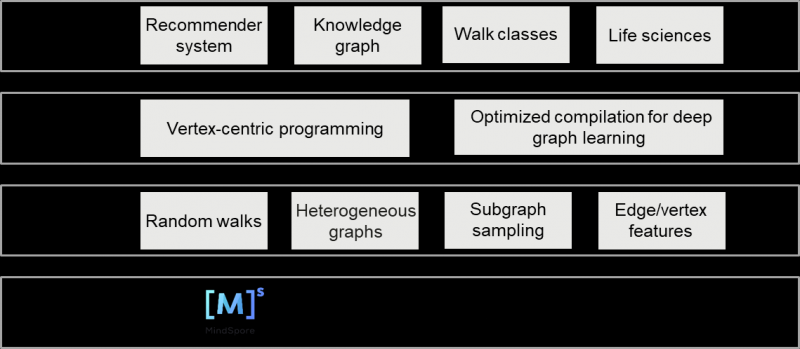
The powerful MindSpore graph learning framework is easy to use and efficient, with more than ten embedded graph learning models available to cover major graph computing scenarios.
Easy to Use: Formulas as code
MindSpore’s vertex-centric programming paradigm is more adaptive to the GNN algorithm logic and Python language than the message passing paradigm. The MindSpore graph learning framework can directly map formulas to code, as shown in the figure below. This means that developers do not need to encapsulate any functions. Instead, they can quickly and directly implement customized GNN algorithms and operations.

Efficient: 3x to 4x faster training
The MindSpore graph learning framework provides a graph kernel fusion feature and the Auto Kernel Generator (AKG). It supports index-based operator fusion in irregular memory access by automatically identifying the unique execution pattern of GNN model tasks and performing fusion and kernel-level optimization. Compared with other frameworks that optimize only common operators, MindSpore is more flexible and scalable, and covers all existing and emerging operators. With the MindSpore all-scenario AI framework as the backend, MindSpore graph learning models accelerate GNN training by 3 to 4 times.

Versatile: Suited to major graph learning networks
The MindSpore graph learning framework has 13 embedded graph learning models, covering homogeneous graphs, heterogeneous graphs, random walks, and others. This allows the framework to be easily integrated into major graph learning networks.
The all-scenario MindSpore aims to lower the entry barriers to AI development, help developers port code more easily, and foster collaboration on demand in all scenarios.
Click the link for more information about how to use MindSpore graph learning models.
Click here to Meet MindSpore and explore more content like this.
Further reading in this series
- How MindSpore Overcomes Bottlenecks in Model Training
- Advancements in Protein Structure Prediction and Inference with MindSpore
- Speaking Your Language: The Transformer in Machine Translation
References
[1] MindSpore 1.6.0 Release Notes. https://gitee.com/mindspore/mindspore/releases/v1.6.0
[2] Graph Learning: A Survey. https://arxiv.org/abs/2105.00696
[3] Representation Learning on Graphs: Methods and Applications. https://www-cs.stanford.edu/people/jure/pubs/graphrepresentation-ieee17.pdf
Article Source: HuaWei
Article Source: HuaWei
Disclaimer: Any views and/or opinions expressed in this post by individual authors or contributors are their personal views and/or opinions and do not necessarily reflect the views and/or opinions of Huawei Technologies.
